Spawn: Direct Cross-Script Calls
The Meepo hard fork in 2024 has introduced a range of enhancements into CKB Script development, with one major innovation being Spawn.
In CKB Script, Spawn refers to a concept and a set of syscalls for creating new processes. Unlike the exec syscall introduced during CKB’s first hard fork in 2021, Spawn enables direct cross-script calls, simplifying development process while offering greater control and optimization.
Why Spawn
The exec syscall, introduced into CKB-VM during CKB’s first hard fork, was designed to enable the loading and executing of a new Script within the current execution space. While powerful, exec can be inefficient, especially when preserving the current execution space is necessary. With exec, all state information of the current Script is discarded. When Script A calls Script B using exec, Script A's context is lost (This means that even if Script A has remaining code after executing exec, that code will not be executed.), as illustrated below:
+----------+ Exec +----------+
----->+ Script A +--------->+ Script B +---->
+----------+ +----------+
We aim to preserve the context of Script A. Ideally, when Script B executes, Script A should be able to retrieve B's execution result and then continue its own execution. This process is illustrated below:
+----------+
----->+ Script A +--------------+----------->
+-----+----+ ^
| |
| Spawn | Exit
v |
+----------+ |
| Script B +--------------+
+----------+
This is where Spawn comes in, fulfilling exactly this purpose.
Development of Spawn in CKB Virtual Machine
The Spawn syscalls in the CKB-VM draw inspiration from Linux standards, offering an efficient method for process creation and using familiar terms like "process," "pipe," and "file descriptor." We've dedicated considerable effort to make this new technology user-friendly, enabling developers to build multi-process applications with the same ease as on a local system.
The term "process" in CKB-VM differs from its meaning in an operating system: in CKB-VM, each running Script is considered a process, essentially an entity with its own independent execution space. However, at the OS level, CKB-VM remains a single-process, single-threaded program.
+--------------------+ .--.
| Hi, CKB, This is | .- \
| 0. Process | /_ \
+-----+ | 1. Pipe | (o ) +-------+
| CKB | | 2. File Descriptor | _/ | | Linux |
+-----+ +--------------------+ (c .-. | +-------+
___ ;; / .' \
.'' ``. ;; O) | \
_/ .-. .-. \_ () () / _ `.__ \ \
(o|( O O )|o) ()(O)() |/ ) / \ \
.' `. ()\ _|_ / \ \
/ (c c) \ \(_ \ / \ \
| | (__) `.______ ( ._/ \ )
\ (o) / (___)`._ .' ) /
`. .' (__) ______ / / /
`-.___.-' /|\ | / /
___)(___ / \ \ / /
.-' `-. `. .' /
/ .-. .-. \ `- /.' /
/ / ( . . ) \ \ / \)| | | |
/ / \ / \ \ / \_\_\_)
\ \ ) ( / / ( /
\ \ ( __ ) / / \ \ \ \
/ ) // \\ ( \ \ \ \ \
(\ / / /\) \\ // (/\ \ \ /) ) \ \ \
-'-'-' .' )( `. `-`-`- .' |.' |
.'_ .' `. _`. _.--' ( (
oOO(_) (_)OOo (__.--._____)_____)
Mechanism and Principles
The new Spawn mechanism consists of two core features:
- Multi-process support
- Pipe-based communication
Alongside these, two new data types are introduced:
- Process ID (PID)
- File descriptor (FD)
Process ID
The concept of Process ID (PID) is similar to that in Unix systems. Each process is assigned a unique ID. The root process always has PID 0, and subsequent processes are assigned incrementally. Even after a process exits, its PID will not be reused.
There are some hard limits to the system to avoid the overuse of resources.
- CKB-VM allows 16 processes to exist at the same time (excluding the root process). Processes that are created but exit normally will not be counted.
- A maximum of 4 instantiated VMs is allowed. Each process needs to occupy a VM instance to run. When the number of processes is greater than 4, some processes will enter a state called "uninstantiated". CKB-VM implements a scheduler to decide which processes should be "instantiated" and which processes should be "uninstantiated". However, switching the instantiation state of a VM is very expensive, developers should try to keep the number of processes below 4 so that all processes are instantiated.
- A child process created by exec retains the same PID as its parent.
- A single transaction may include multiple Scripts, but each Script group is assigned an independent process space.
- PID overflow is not a concern. Process IDs are represented as uint64 (internally implemented as u64). Exhausting the full range would require an astronomically large number of cycles.
File descriptor (FD)
File descriptors are used for pipe operations. They are created via pipe() and released via close(). A maximum of 64 FDs can exist simultaneously
Each FD is created with fixed permissions and is bound to a specific process. It can only be used by that process unless explicitly passed to a child via spawn(). The child retrieves these using inherited_fds().
Key characteristics:
- Although limited to 64 concurrent FDs, FDs can be reused after being closed.
- FD overflow is theoretically possible but practically unreachable before cycle exhaustion.
- FDs are created in pairs (read and write ends), but closing either end invalidates the entire pair.
Multi-Process
The following syscalls are introduced:
spawn: Create a child processprocess_id: Get the current process’s PIDwait: Wait for a child process to exit
Developers use spawn to create child processes. Unlike exec, spawn a process does not discard the parent’s context. Control is transferred to the child, and later returns to the parent once the child exits or when parent-side I/O is needed.
Calling wait switches context to the specified child. If the child performs invalid operations (e.g., deadlocks), the VM may abort execution with an error.
PIPE
To enable inter-process communication, several pipe-related syscalls are introduced:
pipe: Create a unidirectional pipeclose: Close an FDinherited_fds: Retrieve FDs passed from parentread: Read data from an FDwrite: Write data to an FD
Because processes cannot access each other's memory directly, pipes are used to transfer data. Each pipe returns two FDs, one for reading and one for writing. For bidirectional communication, two pipes are typically created.
Additionally, since CKB lacks true parallelism, read and write also serve as mechanisms for notification and scheduling between processes.
Pipes must be created before calling spawn. When spawning, the parent passes one end of the pipe to the child. The child accesses the FD using inherited_fds() and can then operate on it using read, write, and close.
Process Scheduling
CKB-VM does not support parallel execution or time-sliced multitasking. Instead, process switching is cooperative and syscall a form of pseudo-concurrency.
Syscalls such as spawn, wait, read, and write may trigger a context switch. When invoked, the VM switches to the appropriate process stack and resumes execution. When that process completes or triggers another syscall, a similar context switch occurs.
For example, after calling spawn, the VM switches context to the child process and begins executing from its _start.
The diagram below illustrates inter-process communication and scheduling. The example code is from the ckb-rust-script spawn-parent and spawn-child.
(The code is written in Rust but is straightforward enough that developers using other languages can easily follow it. You only need to focus on the spawn-related functions mentioned above.)
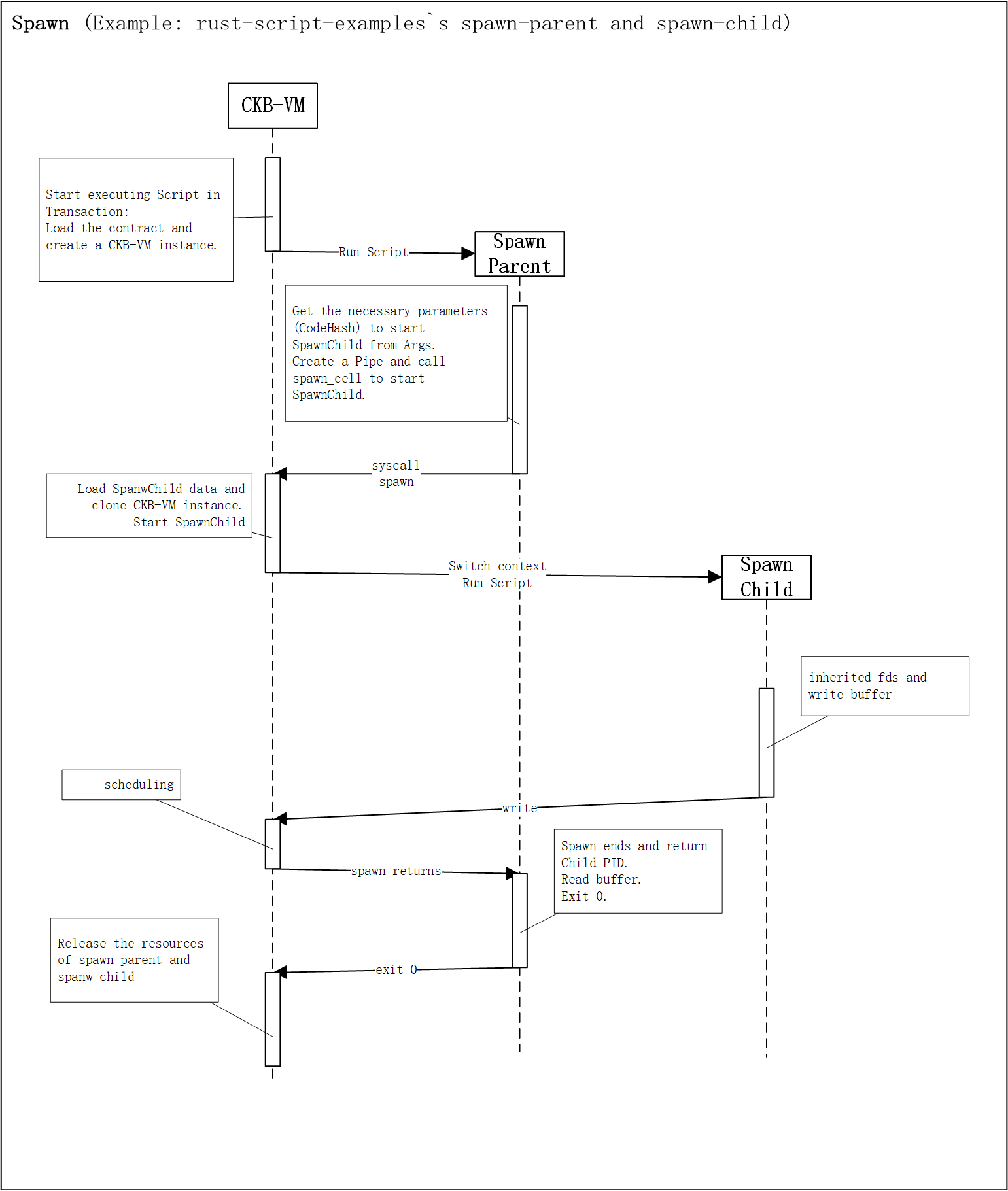
Although a sequence diagram is used, all execution happens within a single physical thread. The diagram merely clarifies logical relationships between processes.
Spawn Functions Overview
In the CKB-VM, Spawn is primarily implemented through the spawn() and spawn_cell() functions, offering nearly the same functionality with the one key distinction: spawn_cell() locates the Script using the code_hash and hash_type, while spawn() requires the developer to provide an absolute index and source.
The function signatures are as follows:
pub fn spawn(
index: usize,
source: Source,
place: usize,
bounds: usize,
spgs: &mut SpawnArgs,
) -> Result<u64, SysError>;
pub fn spawn_cell(
code_hash: &[u8],
hash_type: ScriptHashType,
argv: &[&CStr],
inherited_fds: &[u64],
) -> Result<u64, SysError>;
spawn()
From a low-level perspective, spawn_cell() is simply a wrapper around spawn(). Therefore, I will primarily focus on spawn() function, the parameters for which are explained as follows:
- index: an index value denoting the index of entries to read.
- source: a flag denoting the source of Cells or witnesses to locate, possible values include:
- 1: input Cells
- 0x0100000000000001: input Cells with the same running Script as current Script
- 2: output Cells
- 0x0100000000000002: output Cells with the same running Script as current Script
- 3: dep Cells
- place: A value of 0 or 1:
- 0: read from Cell data
- 1: read from witness
- bounds: high 32 bits means offset; low 32 bits means length. If length equals to zero, it reads to end instead of reading 0 byte.
- spawn_args: pass data during process creation or save return data. It is a structure with four members:
- argc: contains the number of arguments passed to the program
- argv: a one-dimensional array of strings
- process_id: a pointer used to save the process_id of the child process
- inherited_fds: an array representing the file descriptors passed to the child process. It must end with zero. For example, if you want to pass fd1 and fd2, you need to construct an array [fd1, fd2, 0].
The arguments used here—index, source, bounds, place, argc, and argv—are identical to those used in exec().
pipe()
Like Linux, CKB-VM uses pipes and file descriptors to pass data between processes. Here's how it works:
pub fn pipe() -> Result<(u64, u64), SysError>;
The pipe() function creates a pipe—a unidirectional data channel used for interprocess communication. It returns a tuple of two file descriptors representing the pipe's ends. The first descriptor refers to the read end, while the second refers to the write end. Data written to the write end is buffered by CKB-VM until it is read from the read end.
__------__
/~ ~\ +--------------------------------------------+
| //^\\//^\| | Pipes create a unidirectional data channel |
/~~\ || o| |o|:~\ | Data can be written to or read from a pipe |
| |6 ||___|_|_||:| +--------------------------------------------+
\__. / o \/'
| ( O )
/~~~~\ `\ \ /
| |~~\ | ) ~------~`\
/' | | | / ____ /~~~)\
(_/' | | | /' | ( |
| | | \ / __)/ \
\ \ \ \/ /' \ `\
\ \|\ / | |\___|
\ | \____/ | |
/^~> \ _/ <
| | \ \
| | \ \ \
-^-\ \ | )
`\_______/^\______/
read()
The read() function attempts to read up to the number of bytes specified by length from the file descriptor fd into the buffer, returning the actual number of bytes read.
pub fn read(fd: u64, buffer: &mut [u8]) -> Result<usize, SysError>;
write()
The counterpart to the read() function is write(). This syscall writes data to a pipe through a file descriptor. It writes up to the number of bytes specified by length from the buffer, returning the actual number of bytes written.
pub fn write(fd: u64, buffer: &[u8]) -> Result<usize, SysError>;
inherited_fds()
The child Script uses this function to verify its available file descriptors. A file descriptor must— and can only—belong to one process. The file descriptor can be passed when using the spawn() function, as I demonstrated when introducing the spawn().
pub fn inherited_fds() -> Vec<u64>;
close
This syscall manually closes a file descriptor. After calling it, any attempts to read from or write to the file descriptor at the other end will fail.
pub fn close(fd: u64) -> Result<(), SysError>;
wait()
The last function is wait(). The syscall pauses execution until the process specified by pid has completed.
pub fn wait(pid: u64) -> Result<i8, SysError>;
Errors
The Spawn family of syscalls can return five distinct errors. Most of them are self-explanatory and typically occur when you pass incorrect arguments or attempt to double-close a file descriptor.
pub enum SysError {
/// Failed to wait. Its value is 5.
WaitFailure,
/// Invalid file descriptor. Its value is 6.
InvalidFd,
/// Reading from or writing to file descriptor failed due to other end closed. Its value is 7.
OtherEndClosed,
/// Max vms has been spawned. Its value is 8.
MaxVmsSpawned,
/// Max fds has been created. Its value is 9.
MaxFdsCreated,
}
Among these errors, a notable one is OtherEndClosed. This error allows us to implement a function like read_all(fd) -> Vec<u8> to read all the data from the pipe at once. Many programming languages provide similar functions in their standard libraries, and you can easily implement this functionality yourself in the CKB-VM.
pub fn read_all(fd: u64) -> Result<Vec<u8>, SysError> {
let mut ret = Vec::new();
let mut buf = [0; 256];
loop {
match syscalls::read(fd, &mut buf) {
Ok(data) => ret.extend_from_slice(&buf[..data]),
Err(SysError::OtherEndClosed) => break,
Err(err) => return Err(err),
}
}
Ok(ret)
}
Example
Let's walk through a basic example of using spawn. Imagine we want to deploy a public library on the chain, which is quite simple: it receives input parameters, concatenates them, and returns the result to the caller. Let’s see how to implement it.
The main code only consists of the following four lines, where:
- The first line obtains the file descriptor.
- The second line gathers and concatenates all the arguments.
- The third line writes the result to the file descriptor.
- The last line closes the file descriptor.
#[no_mangle]
pub unsafe extern "C" fn main() -> u64 {
let fds = inherited_fds();
let out = ARGS.join("");
write(fds[0], out.as_bytes());
close(fds[0]);
return 0;
}
So, how to use this library? Follow the following code:
- The first line defines the arguments to be passed to the child Script.
- The second line creates a pipe.
- The third line calls the
spawn()function, passing in the arguments and the writable file descriptor. - The fourth line reads all the data from the readable file descriptor.
- The last line uses the
wait()function to wait until the child Script exits.
#[no_mangle]
pub unsafe extern "C" fn main() -> u64 {
let argv = ["Hello", "World!"];
let fds = pipe();
let pid = spawn_cell(code_hash, hash_type, &argv, &[fds[1]]);
let data = read_all(fds[0]);
assert_eq!(&data, b"Hello World!");
wait(pid);
return 0;
}
Enhanced Efficiency With Spawn’s Pipes
Since spawn() operates within its own memory space, independent of the parent process, it can mitigate certain security risks, particularly in scenarios involving sensitive data.
While some other blockchain virtual machines, such as the EVM, also offer cross-contract call functions, these calls tend to be quite expensive, especially when invoking child contracts repeatedly. This is primarily because each call requires continuously creating and destroying a virtual machine, as illustrated below:
+----------+
----->+ Script A +---+------+------------+------+-------+------+--------------->
+----------+ | ^ | ^ | ^
| | | | | |
Create | | Destroy | | | |
v | v | v |
+-+------+-+ +-+------+-+ +-+------+-+
| Script B | | Script B | | Script B |
+----------+ +----------+ +----------+
In contrast, CKB-VM implements pipes, allowing multiple calls to a child Script while only creating and destroying its execution space once. This approach significantly enhances efficiency as shown below:
+----------+
----->+ Script A +----+------------------+------+-------+------+-------+------->
+----------+ | | ^ | ^ ^
| | Pipe | | Pipe | |
Create | | IO | | IO | | Destroy
v | | | | |
+--+-------+ v | v | |
| Script B |----------+------+-------+------+-------+
+----------+
Typical Use Cases
Spawn has several potential applications, and we believe it's particularly advantageous in the following scenarios:
- Public Library: Spawn enables the development of common libraries, allowing different Scripts to reuse shared code. This approach simplifies Script development and substantially reduces deployment costs. For instance, we could publish diverse cryptographic algorithms on CKB as public libraries.
- Large Script Management: When your Script's binary size exceeds 500K, it surpasses CKB's maximum transaction size limit for Script deployment. In such cases, you can leverage Spawn to divide and deploy your Script logic separately, effectively circumventing this limitation.
Conclusion
The Spawn family of functions in the CKB-VM offers an efficient, flexible, and secure method for process creation, particularly in scenarios involving complex Scripts. Using Spawn can boost system performance and security. By mastering the use of spawn(), developers can more effectively manage Scripts while building decentralized applications, unlocking new possibilities in blockchain development.